Pedal to the metal: dynamic templates with Ramhorns

Scratching the Itch
I have a problem. I don't know what to call it, but there is this itch I have when I find something that can obviously be made more efficient. The way I get about scratching that itch these days is by writing some Rust. I just got such an itch when looking at static site generators for this blog, Hugo (written in Go) is pretty much state-of-the art. In Rust land we have Zola, which is feature-rich, mature (for v0.5), and definitely fast enough for most users, and yet it is not as fast as it could be. Being written in Rust is, by itself, not a guarantee of top performance. The implementation matters.
After some looking around I've narrowed down a problem I want to tackle (for now) to one area: template engines. You see, Rust has a plethora of template engines, which typically fall into two categories that I'll refer to as static and dynamic:
- Static template engines grab the source of the template and produce Rust code for rendering it at compile time. This category includes some great libraries like Askama and its derivatives.
- Dynamic template engines load the source of the template and process it somehow at runtime. This category includes Mustache, Handlebars and Zola's own Tera.
For a static site generator, it's imperative that we use a dynamic template engine. We want to be able to ship a compiled binary to the users, but that means we cannot include the templates in the binary. There is a price to pay here: dynamic templates by their nature have to do extra work at runtime. Depending on which library you use, this is usually in the range of 5x-30x slowdown compared to what Askama can do. Even understanding the trade-off, I was still a bit puzzled by the gap, so I did some code reading.
Askama's biggest advantage, being static, is that it can render templates directly from Rust types without having to go through intermediate representation. All of the dynamic engines I've listed above can render templates out of Rust types, but they always create some sort of a dynamic structure first (usually JSON-equivalent recursive enum using serde's Serialize), and those structures almost always use a HashMap, a BTreeMap or similar. Given a struct:
#[derive(Serialize)]
struct Post<'a> {
title: &'a str,
content: &'a str,
}
Rendering has to do something like this:
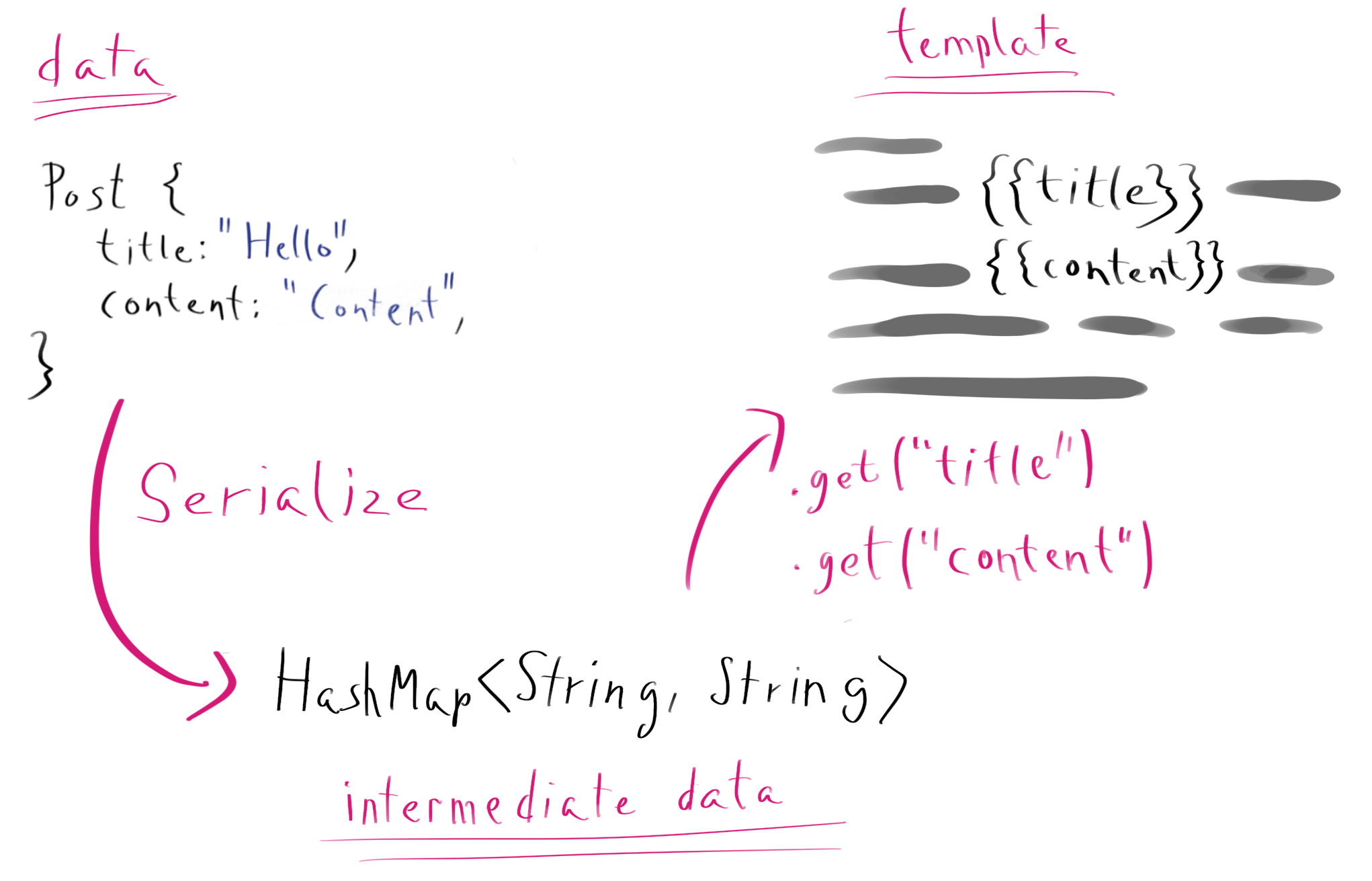
With a HashMap our dynamic template engine can fetch fields by names as strings. Doing that with struct fields would not be possible on runtime. All this is achieved with the generated Serialize trait code that looks as follows:
impl<'a> Serialize for Post<'a> {
fn serialize<S>(&self, serializer: S) -> Result<S::Ok, S::Error>
where
S: Serializer,
{
let mut state = serializer.serialize_struct("Post", 2)?;
state.serialize_field("title", &self.title)?;
state.serialize_field("content", &self.content)?;
state.end()
}
}
This works great, but that intermediate representation costs us dearly, and is completely redundant with the data structure that already exists in memory. HashMap key lookup and insertion times are constant O(1), or close to it, but that doesn't mean they're free. So let's list all the overhead we have here:
- Creating the
HashMapwill cost us heap allocations, doubly so if we are going to convert our field names and values toStrings. - If we have a
Vecor a slice of things to render (like a list of posts), we will have to make a newVecwith and multipleHashMaps inside of that. - For each insertion, the key has to be hashed in order to find the index in the table at which the value should be.
- For each read, the key has to be hashed again in order to find at which index in the table the value is.
This is all work that a static engine does not have to do, field lookup in a struct is effectively free. A dynamic engine cannot do that, so there always has to be some overhead. There is also some overhead due to the fact that we will have to iterate over some template representation when rendering, while a static engine will just follow generated instructions without a loop (unless there is a loop in the template), but that is negligible compared to the serialization costs.
First principles
Let's define our problem:
- We want to be able to render fields from Rust data types with minimal overhead.
- We cannot directly access fields of a struct by their names, but we can do some code-generation with a custom
#[derive]macro. - We aren't compiling templates with our binary, but we're still doing some preprocessing on them that can be done once per template, and the resulting structure can then be reused for each render, so whatever magic we have to do on the template should be pushed into this step.
First, given 2. and 3. we can eliminate one source of the overhead - strings. Instead of comparing strings, we can compare hashes of strings represented as plain u64. 64bit CPUs can compare two u64s with a single CPU instruction. We can do the hashing in the #[derive] macro for the struct, and use the same hasher in template preprocessing. Since the latter is still runtime (although not part of rendering process), ideally we use a fast hashing algorithm. Luckily, we don't need a cryptographically secure algorithm here (I don't expect users to purposefully create collisions), so for that purpose I picked a good and trusted friend of mine - FNV-1a.
If you are interested, the Rust code for such a hasher, on 64-bit values, looks as follows:
fn hash(value: &[u8]) -> u64 {
let mut hash: u64 = 0xcbf29ce484222325;
for byte in value {
hash ^= *byte as u64;
hash = hash.wrapping_mul(0x100000001b3);
}
hash
}
I really, really like this little thing. It's simple, it's elegant, and it feels magical in the way it exploits properties of prime numbers. As one Redditor noted, I could be using an even faster hasher - FxHash - that was originally used in Firefox and is now being used in rustc itself. FxHash is a derivative of FNV that does the same kind of xor multiply magic, but instead of doing it a byte at a time, it loads multiple bytes at a time, which is much faster for long inputs (for short inputs the two are basically identical). I might still do that, but I'd like to research some properties of FxHash, such as randomness and collisions within the English dictionary at very least. 64-bit FNV-1a for that purpose is solid.
Ramhorns
Having that figured out, it was coding time. After some attempts, and some talking to my favorite rubber duck, I've landed with a solution, which is now implemented in Ramhorns. Instead of using Serialize with its derive, Ramhorns is using a Content trait, with a #[derive] macro. For our Post struct above, the generated code looks something like this:
impl<'a> Content for Post<'a> {
fn render_field(&self, hash: u64, buf: &mut String) {
match hash {
// FNV-1a hash of "title"
0xda31296c0c1b6029 => buf.push_str(&self.title),
// FNV-1a hash of "content"
0x420c75b526b35282 => buf.push_str(&self.content),
// In Mustache fashion, do nothing if the field is not found
_ => {},
}
}
}
This is a rather gross oversimplification, there are quite a few more methods there, and the API uses a trait called Encoder instead of a raw String, but the general idea is the same. We've achieved two things:
- We don't need any intermediate structures, we can write fields from the structs directly into our output buffer, which is great!
- The only overhead we have compared to static templates is having to perform one
matchper every{{variable}}in our templates. The time of doing that will depend on the number of fields in the struct, but given that the Rust compiler will optimize this code (ideally producing a jump table for many fields), and thatHashMaplookups still have to do a lot of work, I think it's fair to say that for any real world cases this will be always faster. I don't know if it's the most optimal solution to the problem described here, but I'm pretty sure it's at least very close to it.
Great! Core of the implementation is done! A couple days and 3 minor versions later, Ramhorns is now a proper MVP implementation of Mustache (sans some features). This blog you are reading is rendered with Ramhorns! But is it really fast?
Benchmarks!
As soon as I got something quasi-working, the first thing I did was run benchmarks against other template engines. Here are the results on my machine:
running 5 tests
test a_simple_ramhorns ... bench: 64 ns/iter (+/- 4)
test b_simple_wearte ... bench: 72 ns/iter (+/- 24)
test c_simple_askama ... bench: 181 ns/iter (+/- 9)
test d_simple_mustache ... bench: 736 ns/iter (+/- 133)
test e_simple_handlebars ... bench: 2,889 ns/iter (+/- 118)
I haven't run it against Tera, but the author did and reports being roughly in the Mustache league.
These benchmarks aren't exactly representative of real world scenarios—the render outputs are small, so the result will magnify the cost of serialization. There is a lot of other things that happen during rendering that can make it faster or slower (escaping HTML characters being a prime example), but those are problems that affect static and dynamic engines equally. I'm also not measuring the initial processing times of the templates, but from what little tests I did, I'm also doing very well there (static engines, being static, naturally do zero preprocessing at runtime).
So, the first thing that comes out of those benchmarks is that Ramhorns isn't just faster than the other dynamic engines (which was goal), it ended up being faster than the static ones, too! There are reasons for that. Wearte, having a bit more optimized pipeline than Askama from which it forked, is doing very well. With some optimizations, Askama should easily drop down to ~50ns in this benchmark.
All in all, I'll call this whole experiment a success! I'll continue working on Ramhorns and using it for my own projects. Hopefully this work can serve as inspiration other Rustaceans, and who knows, maybe in a year or two* we can dethrone Hugo from its "world’s fastest" claim!